Parallel Computing (Komputasi Parallel)
Pengertian Komputasi Parallel
Komputasi paralel adalah salah satu teknik melakukan komputasi secara bersamaan dengan memanfaatkan beberapa komputer independen secara bersamaan. Ini umumnya diperlukan saat kapasitas yang diperlukan sangat besar, baik karena harus mengolah data dalam jumlah besar (di industri keuangan, bioinformatika, dll) ataupun karena tuntutan proses komputasi yang banyak. Kasus kedua umum ditemui di kalkulasi numerik untuk menyelesaikan persamaan matematis di bidang fisika (fisika komputasi), kimia (kimia komputasi) dll.

Latar Belakang Mengapa Komputasi Paralel Ada
Pada umumnya sebuah perangkat lunak dibangun dengan menggunakan paradigma komputasi serial, di mana perangkat lunak tersebut dirancang untuk dieksekusi oleh sebuah sebuah mesin yang mempunyai sebuah CPU. Pada komputasi serial, permasalahan diselesaikan dengan serangkaian instruksi yang dieksekusi satu demi satu oleh CPU, di mana hanya satu instruksi yang bisa berjalan pada satu waktu saja. Hal ini akan memunculkan permasalahan untuk eksekusi program yang membutuhkan sumber daya komputasi (prosesor dan memori) yang besar, yaitu waktu eksekusi yang panjang, padahal beberapa instruksi atau kumpulan instruksi sebenarnya dapat dieksekusi secara bersamaan tanpa mengganggu kebenaran program. Permasalahan yang muncul dalam komputasi serial tersebut dapat diatasi dengan menggunakan komputasi paralel, di mana waktu eksekusi program dapat dipersingkat dengan membagi program menjadi task-task yang dapat dikerjakan secara terpisah untuk kemudian dieksekusi secara paralel. Tidak semua task dapat dikerjakan secara terpisah (sebagai contoh adalah penghitungan deret Fibonacci), sehingga tidak semua permasalahan dapat memperoleh keuntungan jika solusi permasalahan tersebut dieksekusi secara paralel. Dalam pembagian task , diperlukan juga pembangunan graf ketergantungan task untuk menentukan ketergantungan antar task (saat suatu task membutuhkan hasil komputasi dari task lain). Pembagian pogram menjadi task -task juga harus memperhatikan granularity (perbandingan antara waktu komputasi dengan waktu komunikasi) dari task -task tersebut. Semakin besar granularity (coarse-grained ), akan semakin kecil beban yang dibutuhkan untuk interaksi antar task.
Tujuan Utama Komputasi Paralel
Tujuan utama penggunaan komputasi paralel adalah untuk mempersingkat waktu eksekusi program yang menggunakan komputasi serial. Beberapa alasan lain yang menjadikan suatu program menggunakan komputasi paralel antara lain :
- Untuk permasalahan yang besar, terkadang sumber daya komputasi yang ada sekarang belum cukup mampu untuk mendukung penyelesaian terhadap permasalahan tersebut.
- Adanya sumber daya non-lokal yang dapat digunakan melalui jaringan atau internet.
- Penghematan biaya pengadaan perangkat keras, dengan menggunakan beberapa mesin yang murah sebagai alternatif penggunaan satu mesin yang bagus tapi mahal, walaupun menggunakan n buah prosesor.
- Adanya keterbatasan kapasitas memori pada mesin untuk komputasi serial.
Hukum yang Berlaku dalam Parallel Processing
- Hukum Amdahl (Inggris: Amdahl’s law) adalah prinsip dasar dalam peningkatan kecepatan proses suatu komputer jika hanya sebagian dari peralatan perangkat keras ataupun perangkat lunak-nya yang diperbaharui/ditingkatkan kinerjanya. Nama Amdahl diambil dari nama seorang arsitektur komputer terkenal di perusahaan IBM, Gene Amdahl yang pertama kali mencetuskan bentuk formulasi ini.
Formulasi atau hukum ini banyak dipakai dalam bidang komputasi paralel untuk meramalkan peningkatan kecepatan maksimum pemrosesan data (secara teoretis) jika jumlah prosesor di dalam komputer paralel tersebut ditambah.
Hukum Amdahl ini dinyatakan dalam bentuk:
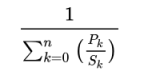
dengan:
adalah prosentase jumlah instruksi
adalah faktor percepatannya (1 menyatakan tanpa percepatan),
menyatakan tiap bagian yang dipercepat/diperlambat, dan
adalah jumlah bagian atau prosesor keseluruhan dalam proses percepatan ini.
2.Hukum Gustafson
Pendapat yang dikemukakan Gustafson hampir sama dengan Amdahl, tetapi dalam pemikiran Gustafson, sebuah komputasi paralel berjalan dengan menggunakan dua atau lebih mesin untuk mempercepat penyelesaian masalah dengan memperhatikan faktor eksternal, seperti kemampuan mesin dan kecepatan proses tiap-tiap mesin yang digunakan.
Hambatan Komputasi Paralel
Penggunaan komputasi paralel sebagai solusi untuk mempersingkat waktu yang dibutuhkan untuk eksekusi program mempunyai beberapa hambatan. Hambatan-hambatan tersebut antara lain adalah :
- Hukum Amdahl : percepatan waktu eksekusi program dengan menggunakan komputasi paralel tidak akan pernah mencapai kesempurnaan karena selalu ada bagian program yang harus dieksekusi secara serial.
- Hambatan yang diakibatkan karena beban jaringan : dalam eksekusi program secara paralel, prosesor yang berada di mesin yang berbeda memerlukan pengiriman dan penerimaan data (atau instruksi) melalui jaringan. Untuk program yang dibagi menjadi task-task yang sering membutuhkan sinkronisasi, network latency menjadi masalah utama. Permasalahan ini muncul karena ketika suatu task membutuhkan data dari task yang lain, state ini dikirimkan melalui jaringan di mana kecepatan transfer data kurang dari kecepatan prosesor yang mengeksekusi instruksi task Hal ini menyebabkan task tersebut harus menunggu sampai data sampai terlebih dahulu, sebelum mengeksekusi instruksi selanjutnya. Jumlah waktu yang dibutuhkan untuk berkomunikasi melalui jaringan antar dua titik adalah jumlah dari startup time, per-hop time, dan per-word transfer time.
- Hambatan yang terkait dengan beban waktu untuk inisiasi task, terminasi task, dan sinkronisasi.
Arsitektur Komputasi Paralel
Taksonomi Flynn membagi arsitektur komputer paralel dengan menggunakan sudut pandang instruksi dan data, sehingga terdapat empat jenis arsitektur komputer paralel :
- SISD (Single Instruction, Single Data). Arsitektur ini adalah arsitektur yang mewakili komputer serial, di mana hanya ada satu prosesor dan satu aliran masukan data (memori) sehingga hanya ada satu task yang dapat dieksekusi pada suatu waktu. Arsitektur von Neumann termasuk dalam jenis ini. SISD adalah satu-satunya yang menggunakan arsitektur Von Neumann, Ini dikarenakan pada model ini hanya digunakan 1 processor saja. Oleh karena itu model ini bisa dikatakan sebagai model untuk komputasi tunggal. Sedangkan ketiga model lainnya merupakan komputasi paralel yang menggunakan beberapa processor. Beberapa contoh komputer yang menggunakan model SISD adalah UNIVAC1, IBM 360, CDC 7600, Cray 1 dan PDP 1.

- SIMD (Single Instruction, Multiple Data). Pada arsitektur ini, eksekusi sebuah instruksi akan dilakukan secara bersamaan oleh beberapa prosesor, di mana suatu prosesor dapat menggunakan data yang berbeda dengan prosesor lain. Karakteristik lain dari arsitektur ini adalah alur eksekusi instruksi yang deterministik (state dari instruksi dan data pada suatu waktu dapat dengan mudah diketahui). Arsitektur ini cocok untuk program yang dapat dibagi menjadi task-task yang mempunyai derajat keteraturan yang tinggi, misalnya sistem pengolah grafik. SIMD menggunakan banyak processor dengan instruksi yang sama, namun setiap processor mengolah data yang berbeda. Sebagai contoh kita ingin mencari angka 27 pada deretan angka yang terdiri dari 100 angka, dan kita menggunakan 5 processor. Pada setiap processor kita menggunakan algoritma atau perintah yang sama, namun data yang diproses berbeda. Misalnya processor 1 mengolah data dari deretan / urutan pertama hingga urutan ke 20, processor 2 mengolah data dari urutan 21 sampai urutan 40, begitu pun untuk processor-processor yang lain. Beberapa contoh komputer yang menggunakan model SIMD adalah ILLIAC IV, MasPar, Cray X-MP, Cray Y-MP, Thingking Machine CM-2 dan Cell Processor (GPU).

- MISD (Multiple Instruction, Single Data). Pada arsitektur ini, berbagai instruksi akan dieksekusi secara bersamaan oleh beberapa prosesor dengan menggunakan data yang sama. Arsitektur ini kurang populer karena hanya sedikit permasalahan yang membutuhkan solusi dengan menggunakan karakteristik arsitektur ini. Contoh permasalahan yang mungkin membutuhkan arsitektur ini antara lain adalah multiple frequency filter dan program pemecah sandi yang menggunakan beberapa algoritma kriptografi sekaligus. MISD menggunakan banyak processor dengan setiap processor menggunakan instruksi yang berbeda namun mengolah data yang sama. Hal ini merupakan kebalikan dari model SIMD. Untuk contoh, kita bisa menggunakan kasus yang sama pada contoh model SIMD namun cara penyelesaian yang berbeda. Pada MISD jika pada komputer pertama, kedua, ketiga, keempat dan kelima sama-sama mengolah data dari urutan 1-100, namun algoritma yang digunakan untuk teknik pencariannya berbeda di setiap processor. Sampai saat ini belum ada komputer yang menggunakan model MISD.

- MIMD (Multiple Instruction, Multiple Data). Pada arsitektur ini, berbagai instruksi dapat dieksekusi oleh beberapa prosesor di mana masing-masing prosesor dapat menggunakan data yang berbeda. Eksekusi instruksi pada arsitektur ini dapat dilakukan secara sinkron (pada suatu rentang waktu, jumlah instruksi yang dieksekusi oleh semua prosesor adalah sama) maupun asinkron, deterministik maupun non-deterministik. Selain itu, arsitektur ini dapat melakukan pekerjaan sesuai dengan karakteristik dari ketiga asitektur sebelumnya. MIMD menggunakan banyak processor dengan setiap processor memiliki instruksi yang berbeda dan mengolah data yang berbeda. Namun banyak komputer yang menggunakan model MIMD juga memasukkan komponen untuk model SIMD. Beberapa komputer yang menggunakan model MIMD adalah IBM POWER5, HP/Compaq AlphaServer, Intel IA32, AMD Opteron, Cray XT3 dan IBM BG/L.




Perbedaan antara Komputasi Tunggal dengan Komputasi Parallel :
1. Komputasi Tunggal

2. Komputasi Parallel

Arsitektur Memori pada Komputasi Paralel
Pada umumnya, ada dua buah arsitektur memori pada komputer paralel, yaitu shared memory dan distributed memory.
Shared memory
Arsitektur ini menyediakan global addressing sehingga berbagai prosesor mempunyai cara pengaksesan memori yang seragam. Setiap perubahan pada suatu lokasi memori oleh suatu prosesor akan selalu terlihat oleh prosesor lain. Kelebihan dari arsitektur ini antara lain adalah pengaksesan memori yang user friendly dan performansi yang baik dalam penggunaan data bersama antar task. Sedangkan kekurangannya antara lain adalah kurangnya skalabilitas ketika terjadi penambahan prosesor, di mana akan terjadi peningkatan traffic antara prosesor ke shared memory dan antara cache coherent system dengan memori sebenarnya.
Berdasarkan frekuensi akses, ada dua jenis shared memory :
- Uniform Memory Access (UMA). Setiap prosesor memiliki hak pengaksesan yang seragam dengan prosesor lain
- Non Uniform Memory Access (NUMA). Tidak semua prosesor memiliki hak yang sama dalam mengakses memori
Distributed memory
Arsitektur ini mempunyai karakteristik di mana setiap prosesor memiliki memorinya masing-masing, sehingga eksekusi instruksi dapat berjalan secara independen antara satu prosesor dengan yang lain. Prosesor akan menggunakan jaringan ketika membutuhkan akses ke memori non lokal. Akses ini sepenuhnya menjadi tanggung jawab penulis program. Kelebihan dari arsitektur ini adalah terjaganya skalabilitas ketika terjadi penambahan prosesor. Sedangkan kekurangannya adalah penulis program harus berurusan dengan detail komunikasi data antara prosesor dan memori non lokal.
Distributed Processing atau Distributed Computing System adalah sekumpulan peralatan pemrosesan yang saling terhubung melalui jaringan komputer dan saling bekerjasama untuk mengerjakan tugas-tugas tertentu. Yang dimaksud dengan peralatan pemrosesan dataadalah peralatan komputasi yang dapat mengeksekusi sendiri sebuah program.
Sekumpulan peralatan yang saling terhubung akan mendistribusikan berbagai macam hal, dianataranya adalah:
- Processing Logic / Pemrosesan secara logis
- Fungsi. Beberapa fungsi sistem komputer dapat didelegasikan ke beberapa hardware atau software
- Data
- Kontrol
Kriteria Distributed Processing
Pemrosesan terdistribusi (Distributed Processing) dapat dikelompokkan berdasarkan beberapa kriteria, yaitu:
- Degree of Computing / tingkat hubungan : Tinggi atau rendah ? Jumlah data yang saling digunakan dibandingkan dengan jumlah pemrosesan lokal
- Struktur antar hubungan : kuat atau lemah ? Jika komponen di Share dikatakan kuat ?
- Kesalingtergantungan komponen-komponen : Kuat atau lemah dalam mengekseskusi proses.
- Keselarasan antar komponen : selaras atau tidak selaras ?
Thread Programming
Threading / Thread adalah sebuah alur kontrol dari sebuah proses. Konsep threading adalah menjalankan 2 proses ( proses yang sama atau proses yang berbeda ) dalam satu waktu.
Contoh:
Sebuah web browser mempunyai thread untuk menampilkan gambar atau tulisan sedangkan thread yang lain berfungsi sebagai penerima data dari network.
Threading dibagi menjadi 2, yaitu :
- Static Threading. Teknik ini biasa digunakan untuk komputer dengan chip multi processors dan jenis komputer shared-memory lainnya. Teknik ini memungkinkan thread berbagi memori yang tersedia, menggunakan program counter dan mengeksekusi program secara independen. Sistem operasi menempatkan satu thread pada prosesor dan menukarnya dengan thread lain yang hendak menggunakan prosesor itu.
- Dynamic Multithreading. Merupakan pengembangan dari teknik sebelumnya yang bertujuan untuk kemudahan karena dengannya, programmer tidak harus pusing dengan protokol komunikasi, load balancing, dan kerumitan lain yang ada pada static threading. Concurrency platform ini menyediakan scheduler yang melakukan load balacing secara otomatis. Walaupun platformnya masih dalam pengembangan namun secara umum mendukung dua fitur (Nested parallelism dan Parallel loops).
Perkembangan di Indonesia
Di Indonesia, usaha untuk membangun infrastruktur mesin paralel sudah dimulai sejak era 90-an, meski belum pada tahap serius dan permanen. Namun untuk pemrograman paralel sudah sejak awal menjadi satu mata-kuliah wajib di banyak perguruan tinggi terkait. Baru pada tahun 2005 dimulai pembuatan infrastruktur mesin paralel permanen, misalnya yang dikembangkan oleh Grup Fisika Teoritik dan Komputasi di P2 Fisika LIPI. Didorong oleh perkembangan pemrograman paralel yang lambat, terutama terkait dengan sumber daya manusia (SDM) yang menguasainya, mesin paralel LIPI ini kemudian dibuka untuk publik secara cuma-cuma dalam bentuk LIPI Public Cluster (LPC). Saat ini LPC telah dikembangkan lebih jauh menjadi gerbang komputasi GRID di Indonesia dengan kerjasama global menjadi IndoGRID.
Pada tahun berikutnya, dengan dukungan dana dari proyek Inherent Dikti, Fasilkom UI juga membangun mesin paralel. Sementara itu pada tahun 2009, ITB membuat kluster hibrid CPU dan GPU yang pertama di Indonesia dengan kemampuan hingga 60 inti CPU dan 1920 inti GPU.
Sumber
- https://andri102.wordpress.com/game/soft-skill/konsep-komputasi-parallel-processing/
- https://id.wikipedia.org/wiki/Komputasi_paralel
- https://bestchildrenofgod.wordpress.com/kinerja-komputasi-dengan-parallel-processing/
- http://anderzt.blogspot.com/2016/04/tugas-makalah-komputasi-paralel.html
Tidak ada komentar:
Posting Komentar